
In recent years we have seen numerous cases of DDoS attacks on servers. In these types of attacks, servers are overwhelmed with fake requests (which they still have to handle) from the attacker. Consequently the server becomes saturated and is unable to serve the users it should, causing the web application to collapse.
Recently while searching for information on the subject I discovered that there is a type of denial-of-service attack that uses regular expressions to do so. This attack, known as ReDoS (from the English Regular expression Denial of Service), has the same effect as a normal DDoS attack, but using extreme cases at points where regular expressions are used.
Regular expressions allow us to find patterns in character strings. To do this, the regular expression resolution algorithm checks that each character matches the pattern we have provided. The problem comes when, for a given input, it finds multiple possible paths (as if solving a maze with several exits).
The Origin of the Problem#
The classic algorithm for constructing regular expressions uses a Nondeterministic Finite Automaton (NFA), a finite state machine where each state-symbol pair can have multiple following states.
Therefore, the automaton performs the transition to the end of the input for each of those possible states. To avoid falling into an infinite loop, a deterministic algorithm is used, but this tries all possible paths one by one until it finds a match, or until all paths have been tried and it fails.
For example, the expression ^(a+)+$ can be represented with the following automaton:
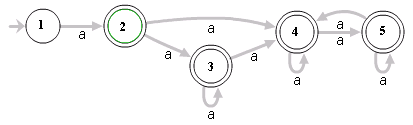
For the input aaaaX, the automaton would find 16 possible paths. But for the input aaaaaaaaaaaaaaaaX there would be 65,536 possible paths, and the number would double for each additional "a" added.
Although not all regular expression resolution algorithms use this type of automaton, some of them are still used today for efficiency. Therefore, the problem would lie in rewriting the regular expression so that the number of steps the automaton has to take is not so large and, consequently, the resolution time is not exponential.
"Evil" Regular Expressions (Evil Regex)#
The main problem, and what ReDoS attacks exploit, is that we sometimes create "evil" or "evil regex" regular expressions. These are expressions in which the code can get stuck when encountering infinite solutions for a specific input. An "evil regex" contains grouping with repetition, and within the group another repetition with overlapping alternation.
Some examples of "evil regex" that work for the input aaaaaaaaaaaaaaaaaaaaaaaa! would be:
(a+)+([a-zA-Z]+)*(a|aa)+(a|a?)+(.*a){x} | for x > 10
An attacker could look for points in the code susceptible to using a regular expression (for example, validating an email or a password) in search of an "evil regex" portion, to provide the system with the exact input that crashes it.
It is important to realize that an "evil regex" does not necessarily have to return an infinite amount of time to be considered as such. A sufficiently large resolution time would also cause the system to collapse if thousands (or millions) of users try to exploit the same vulnerability at the same time.
The Web Is "Regex-Based"#
Although it may seem like a superficial or not very important type of attack, the truth is that the modern web is based on regular expressions. Web development (from the typical WordPress page to more complex systems like Twitter) needs regular expressions to validate that the data being handled meets certain standards.
A very common case is client-side form validation. For example, when we try to register on a website and after entering our desired password it says "your password must contain at least one uppercase letter." Without regular expressions, this type of check would be unfeasible to program due to the infinite possible combinations.
Wherever there is a regular expression, there is a risk that an "evil regex" exists that an attacker could use to crash the system. The dangerous thing is that if an attacker finds an "evil regex" on the client side, the same "evil regex" most likely exists on the server side. And crashing the interface is a problem, but crashing the server is a much bigger problem.
Example#
Suppose we are implementing a registration system, and in the form we do not want to allow the password to include the username. We might have something like this:
String userName = textBox1.Text; String password = textBox2.Text; Regex testPassword = new Regex(userName); Match match = testPassword.Match(password); if (match.Success) { MessageBox.Show("Do not include name in password."); } else { MessageBox.Show("Good password."); }
This small piece of code creates a regular expression based on the username entered by the user, then checks that the password is not contained within it. The problem would come if an attacker entered an "evil regex" as the username (for example, ^(([a-z])+.)+[A-Z]([a-z])+$) and as the password an input that crashes the system (for example, aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!).
How to Avoid This Problem?#
Short answer: it is very difficult. Plain and simple. The examples we have seen are fairly simple, but when we talk about validating much more complex data (for example, an email), the combinations grow and it becomes quite difficult not to fall into the error of using an "evil regex" at some point.
As a recommendation, it is usually suggested to be careful with "repetitions of repetitions," and to be very clear about when to use an asterisk (*, zero or more repetitions) and the plus sign (+, one or more repetitions) together. It is common to fall into the error of concatenating "repetitions of repetitions" using both operators, and that could result in a near-infinite amount of time for certain inputs.
Another possible solution that is recommended is to wrap the expression in an atomic group to avoid the "backtracking" problem; that is, if when testing a combination it reaches a dead end, the expression would not go back to the previous step and continue trying alternative paths (as if it were a maze), but would go directly to the start of the group and discard all those "paths" that remained to be explored during the check.
Despite this, there are tools that allow us to check the number of steps a regular expression needs to find a solution, or to check whether "evil regex" exist in our regular expressions:
Related Links#
- How a Regex Engine Works
- ReDoS (Wikipedia)
- How can I recognize an evil regex? (Stack Overflow)
- Regular expression Denial of Service - ReDoS
- Regular Expressions Denial of the Service (ReDOS) Attacks: From the Exploitation to the Prevention
- Runaway Regular Expressions: Catastrophic Backtracking
- Regular Expression Matching Can Be Simple And Fast (but is slow in Java, Perl, PHP, Python, Ruby, ...)
- xkcd: Perl Problems