
En los últimos años hemos visto numerosos casos de ataques DDoS a servidores. En este tipo de ataques los servidores son ahogados con peticiones falsas (pero que debe atender) por parte del atacante. Consecuentemente el servidor se ve saturado y no es capaz de dar servicio a los usuarios que debería, haciendo que la aplicación web colapse.
Recientemente buscando información al respecto he descubierto que existe un tipo de ataque de denegación de servicio, pero usando para ello las expresiones regulares. Este ataque, conocido como ReDoS (del inglés Regular expression Denial of Service) tiene como consecuencia el mismo efecto que un ataque DDoS normal, pero usando casos extremos en puntos donde se utilizan expresiones regulares.
Las expresiones regulares nos permiten encontrar patrones en cadenas de caracteres. Para ello, el algoritmo de resolución de expresiones regulares va comprobando que cada carácter vaya cumpliendo el patrón que le hemos proporcionado. El problema viene cuando para una entrada encuentra varios caminos posibles (como si estuviera resolviendo un laberinto que tuviera varias salidas).
El origen del problema#
El algoritmo clásico para la construcción de expresiones regulares utiliza un autómata finito no determinista (Nondeterministic Finite Automaton, NFA), una máquina de estados finita donde cada par de estado - símbolo puede tener varios estados que le sigan.
Por tanto, el autómata realiza la transición hasta el final de la entrada por cada uno de esos posibles estados. Para no caer en el infinito, se utiliza un algoritmo determinista, pero este intenta uno por uno todos los posibles caminos hasta que encuentra una coincidencia, o hasta que ha intentado todos los caminos y falla.
Por ejemplo, la expresión ^(a+)+$ puede ser representada con el siguiente autómata:
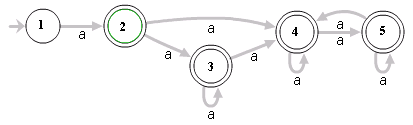
Para la entrada aaaaX, el autómata encontraría 16 posibles caminos. Pero para la entrada aaaaaaaaaaaaaaaaX habrían 65.536 posibles caminos, y el número se duplicaría por cada letra "a" adicional que añadiéramos.
A pesar de que no todos los algoritmos de resoluciones de expresiones regulares utilizan este tipo de autómatas, algunos de ellos aún siguen usándose hoy en día por eficiencia. Por tanto, el problema recaería en reescribir la expresión regular para que el número de pasos que deba dar el autómata no sea tan grande y, por tanto, el tiempo de resolución no fuera exponencial.
Expresiones regulares "malvadas" (Evil Regex)#
El principal problema, y de lo que se aprovechan los ataques ReDoS, es que en ocasiones creamos expresiones regulares "malvadas" o "evil regexes". Este tipo de expresiones son aquellas en las que el código puede quedarse bloqueado al encontrar infinitas soluciones para una entrada concreta. Una "evil regex" contiene agrupación con repetición, y dentro del grupo otra repetición con alternación con solapamiento.
Algunos ejemplos de "evil regex" que funcionan para la entrada aaaaaaaaaaaaaaaaaaaaaaaa! serían:
(a+)+([a-zA-Z]+)*(a|aa)+(a|a?)+(.*a){x} | for x > 10
Un atacante podría buscar sitios en el código susceptibles de usar una expresión regular (por ejemplo, validar un email o una contraseña) en busca de una porción "evil regex", para proporcionarle al sistema la entrada exacta que bloquee el sistema.
Es importante darse cuenta que una "evil regex" no necesariamente debe devolver un tiempo infinito para ser considerada como tal. Un tiempo de resolución suficientemente grande también conllevaría el colapso del sistema en caso de que miles (o millones) de usuarios intenten explotar la misma vulnerabilidad al mismo tiempo.
La Web es "regex-based"#
Aunque pueda parecer un tipo de ataque superficial o no muy importante, lo cierto es que la web actual está basada en expresiones regulares. El desarrollo web (desde la típica página en Wordpress hasta sistemas más complejos como Twitter) necesita las expresiones regulares para validar que los datos que se manejan cumplan ciertos estándares.
Un caso muy típico suele ser la validación de formularios en cliente. Por ejemplo, cuando nos intentamos registrar en una web y al introducir nuestra contraseña deseada nos dice "su contraseña debe contener al menos una mayúscula". Sin las expresiones regulares, este tipo de comprobaciones sería inviable de programar debido a las infinitas combinaciones posibles.
Donde haya una expresión regular, hay riesgo de que exista una "evil regex" que un atacante podría usar para colgar el sistema. Lo peligroso del asunto es que si un atacante encuentra una "evil regex" en cliente, lo más probable es que la misma "evil regex" exista en servidor. Y que consigan bloquear la interfaz es un problema, pero que consigan bloquear el servidor es un "problemón".
Ejemplo#
Supongamos que estamos implementando un sistema de registro, y en el formulario no queremos permitir que la contraseña incluya el nombre de usuario. Podríamos tener algo como esto:
String userName = textBox1.Text; String password = textBox2.Text; Regex testPassword = new Regex(userName); Match match = testPassword.Match(password); if (match.Success) { MessageBox.Show("Do not include name in password."); } else { MessageBox.Show("Good password."); }
Este pequeño código crea una expresión regular basada en el nombre introducido por el usuario, para luego comprobar que la contraseña no esté incluida en él. El problema vendría si un atacante introdujera como nombre de usuario una "evil regex" (por ejemplo, ^(([a-z])+.)+[A-Z]([a-z])+$) y como contraseña una entrada que bloqueara el sistema (por ejemplo, aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!).
¿Cómo evitar este problema?#
Respuesta corta: es muy difícil. Así de simple. Los ejemplos que hemos visto son bastante sencillos, pero cuando hablamos de validar datos mucho más complejos (por ejemplo, un email) las combinaciones crecen y es bastante complicado no caer en el error de usar una "evil regex" en algún momento.
Como recomendación se suele plantear tener cuidado con las "repeticiones de repeticiones", y tener muy claro cuando usar un asterisco (*, ninguna o infinitas repeticiones) y el más (+, uno o infinitas repeticiones) conjuntamente. Es común caer en el error de concatenar "repeticiones de repeticiones" usando ambos operadores, y eso podría incurrir en un tiempo casi infinito para según qué entradas.
Otra de las posibles soluciones que recomiendan es encapsular la expresión en un grupo atómico para evitar el problema de "backtracking"; es decir, si al probar una combinación llega a un camino sin salida, la expresión no volvería al paso anterior y seguiría probando caminos alternativos (como si fuera un laberinto), sino que iría directamente al inicio del grupo y descartaría todos esos "caminos" que han quedado por mirar en el transcurso de la comprobación.
Pese a ello, existen herramientas que nos permiten comprobar el número de pasos que necesita una expresión regular para hallar una solución, o comprobar si existen "evil regex" en nuestras expresiones regulares:
Enlaces relacionados#
- How a Regex Engine Works
- ReDoS (Wikipedia)
- How can I recognize an evil regex? (Stack Overflow)
- Regular expression Denial of Service - ReDoS
- Regular Expressions Denial of the Service (ReDOS) Attacks: From the Exploitation to the Prevention
- Runaway Regular Expressions: Catastrophic Backtracking
- Regular Expression Matching Can Be Simple And Fast (but is slow in Java, Perl, PHP, Python, Ruby, ...)
- xkcd: Perl Problems